
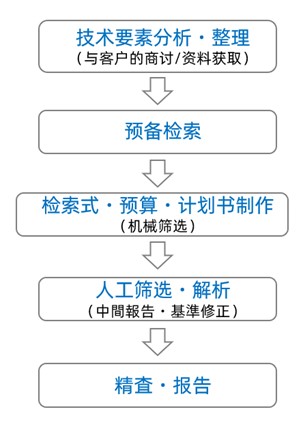
日本式专利调查的流程
日本式专利调查的流程
这里我们画了一个流程图,主要分为以下5个步骤:
钓鱼式 or 撒网式?
日本式专利调查风格:重视检索方法(检索式)的再现性,严防漏检,风险意识高。
关于专利调查的风格,钓鱼式的具体代表是美国式的调查方法,只要能检索出最相近、最危险的、最有力的专利,就可以了。
但日本的调查方法是不一样的,日本式的风格是撒网式的,相关的专利要一个不漏的都筛选出来。对漏检非常重视,很谨慎,宁愿多花成本,也要尽可能地排除潜在的风险。即使很细小的风险,也不放过。
日本式的专利调查首先要有系统的检索式,有检索式方便评价检索的可靠性。不能这边列几个关键词检索一下,出来了几篇相关文件加进去,那边又换了个想法又检索出几篇加进去。除了当事人调查员,其他人都不清楚是个怎样的检索过程,这在日本是行不通的。这样出来的调查报告,如果后续有异议的话,因为检索过程不能再现,就搞不清楚哪里出问题了。
有多个角度的检索想法的话,就要分别制作多个检索式,然后汇总起来系统调查。
确保检索过程可以再现的,要有检索式,要标明检索日期、使用的数据库、检索范围等,这样换个人也能看得明明白白清清楚楚。
整个团队里都能确认、验证、点评,这样即使可能还会有漏检的风险,但也基本是在可预测可控制的范围内。让人安心很多!
(1)技术要素的分析・整理
专利调查流程第一步,首先是听客户需求,确定调查对象。一般调查公司和客户会先开个沟通会,公司知识产权部的人,技术生产部门的人,有时候也会有第三方事务所的弁理士参加。客户先介绍下背景,为什么做这个调查,具体的技术内容是什么,想做到什么程度,目前自己简单调查了下是个什么情况等等。客户一般还会给一些书面材料,记载的技术细节更详细一些。这个阶段差不多就沟通好具体的调查内容了。
(2)预备检索
然后就进行预备检索,这个阶段主要查找近似文献,从而确定分类号和关键词。中国专利的话是看IPC分类,欧美专利的话要用到CPC分类,而日本专利的话是用FI分类和F-term,日本用的这个分类比IPC分类的更详细。FI和F-term分类,是日本专利局自己定义的分类,属于日本独有的分类。FI在IPC四级分类的基础上进一步细化了。
另外,检索不同国家的专利,也会相对应地使用不同的数据库。
下图是分类号体系的对比。
可以看出比如H01L21/306这个分类,IPC的话只有一个,FI的话下层还细分了好多分类。各种分类号体系并不是一一对应的,IPC算是最简单的。像CPC的话,有时候同一个定义,位置和IPC的完全不一样,如果没有一定的经验的话,很可能会漏掉或者选择了错误的分类号。要特别注意,尤其在检索不同国家专利的时候。

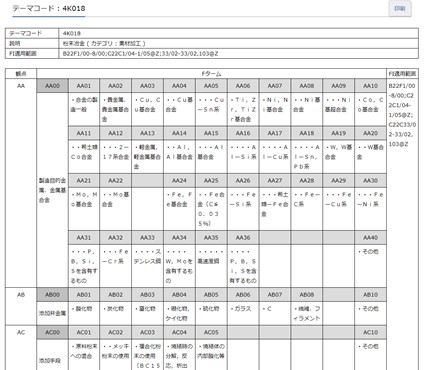
下面的这个表格截取的是日本的F-term分类表格,这个就又比FI分类要细分很多,而且与其他分类体系完全不对应。属于日本独有的分类。
预备检索阶段,本文举了一个列子(下面的截图)。检索日本专利时,可以使用日本专利局官方的数据库J-PlatPat,这个系统的检索页面很简单,正式检索的时候是不够用的,不过预备检索阶段,找几篇近似专利的话,主要通过关键词检索,这个界面也就够用了。

通过预备检索,我们找到其中最相近的几篇专利。下面这个表格,就是我们预备检索阶段找出来的最相近的几篇专利,这里我们需要提取他们的分类号。中国专利的话就是IPC分类号,日本专利的话要提取FI和F-term分类号(此图上没有标注)。另外,我们找的这些近似专利最好是不同的申请人的。因为同一个申请人一般倾向于使用相同的或者差不多的分类号,要找不同申请人的,找出来的文献要尽可能用的是不同的分类号,这样才能在分类号上网络全面。

类似专利里出现的IPC/FI/F-term分类,每个分类对应的定义是什么,去看一下。上图的下面这个表格截取了一部分来举例说明,每个分类的上层分类的定义是什么,有没有下层分类,都看一看。基于我们要调查的技术内容,需要的分类就选取出来,不需要的分类就删掉。
找分类号的时候,还有一点需要注意。分类号会定期修改、增减,你常用的查看分类的网站更新的是否及时,要看一下。比如,今年2021年1月份IPC分类又进行了一次修订,里面关于电池的H01M2这个分类删掉了,相应的新增了H01M50这个分类。以前用的H01M2的分类,今年开始要去M50里面去找了,但目前很多网站包括中国专利局的官网上都还没有更新这个分类。
下面的表格是我们预备检索阶段搜罗的关键词。举的这个例子,它是日本专利、中国专利、欧美专利都调查的,所以相应的日语、汉语、英语的检索关键词要分别列出来,检索式也需要分别制作。

关键词的选取,要特别注意要找的尽可能全面些,不要漏选。
(3)检索式・预算・计划书制作
预备检索做完之后,我们就可以基于选定的分类号和关键词来制作正式的检索式了。下图就是一个正式的检索式。
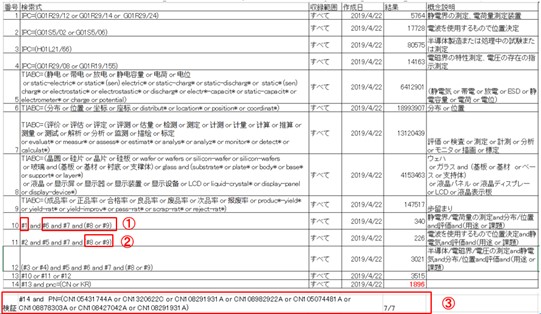
①IPC*关键词:同一概念的IPC/KW归整在一行。
②多角度组合逻辑式。
③类似专利公报号码的验证:若不包含,需对分类/KW/式子逻辑等进行调整。
这举得是一个中国专利检索的例子,用了IPC分类号和中文、英文关键词。同一个概念规整在一行里,这样比较容易看。式子考量的时候,要尽量从多个角度检索。比如这里例子里,10、11、12这三个式子就是从三个角度来组合的逻辑检索式。
最后,我们检索出来的这个结果要验证一下可靠性。比如,这里最下面我们检索出来1896件,可以用预备检索阶段找出来的类似专利的专利号代入进去,验证一下有没有漏检。这个例子里,类似的7件专利都通过验证,即都包含在这1896件里面了。如果有几件没有包含进去,就需要找原因,是IPC、关键词漏了,还是逻辑组合有问题,这时候需要对检索式重新调整。
下图是关键词考量上的一些细节。比如,我们要搜索【头发定型剂】,那么它的关键词就有两种输入方式,一种是整体概念当成一个关键词,即蓝色字体写的【摩丝,发胶,定型啫喱,弹力素等】,另一种就是把【头发定型剂】这个词分成两个概念,【头发】是一个概念,【定型】又是一个概念,把这两概念分解再重新组合,下图里用红色字体标出来了。【头发】相关的关键词【毛发 or 头发 or 发用 or 发型】是一部分,【定型】相关的关键词【造型or 塑形or 固定 or 凝胶 or 啫喱】是另一部分,两个部分结合起来一起用。日本专利里面的用语也是一样的,有的专利会写【本发明是关于一种整发剂,其成分有。。。】,但有的专利就不这么直接写常见名称,它可能会写【本发明是关于一种头发固定用组合物,其包含。。。】等。所以关键词选取的时候,要发挥想象力,考虑所有这些可能出现的情况,要尽可能地包络全面。

另外,检索不同国家的专利时,用的关键词也会有一定区别。比如这里【头发】的【发】这一个字,我们检索中国专利的时候是不能用的,因为汉语里面头发的【发】和发明的【发】是一个字,基本上所有的专利都会用到这个字,因为每件专利基本都会写【本发明是一种。。。的发明】。那你把这个【发】字输进去的话,基本上所有的专利都出来,完全起不到筛选的效果,所以一定要再加一个字,【发用】、【美发】之类的。但这个字在检索日本专利时是需要放进去的,因为日语的头发的【髪】和发明的【発】不是一个字,如果你不放进去,反而会造成漏检。
另外,还有一些关键词,可以根据客户的要求不放进去,比如,这里【发蜡 or 发泥 or 发膏 or 蓬松粉】也都包含在【头发定型剂】这个意思里,但是客户已经明确说明,只检索液体类,那么蜡状、膏状、粉末状的关键词就可以不放。
不放的意思是,不积极地检索这几个词,并不是说使用not把含有这几个词的专利去掉,not一定要慎用。我们可以不积极的检索蜡状、膏状、粉末状的头发定型剂专利,但是检索液体定型剂的时候,顺便带出来了,涉及多种形状用途的定型剂,这些专利我们还是要的。
再补充几点制作检索式阶段的注意点,比如预防漏检的对策之一,除了刚刚我们提到的几点以外,可以在原文语言外,加上英语的词汇(仅适用可以多语言检索的DB)。

另外,刚刚说过的IPC分类号有修订的情况,新的分类号和旧的分类号都需要找出来。
关键词的选择,再举一个列子。比如我们检索化学组合物,里面的成分之一NaCl,针对这个词的关键词选择,食盐、油盐酱醋的【盐】是NaCl的意思,但是化学里各种盐化合物都带有这个【盐】字,所以考虑NaCl的关键词时不能使用【盐】字,否则就把所有的盐类化合物都检出来了,尤其是化学组合物的专利,大部分都有这个字,完全不能起到过滤的作用。
另外,检索式里还会根据情况加上法律状态或者时间的限制。比如,侵权预防调查时,要排除已经失效的专利,只看有效和审查中的专利。无效证据检索的话,要限定某一时间截点之前公开的专利。再比如,同样是侵权预防调查,但客户这个项目是明年4月份才上,那么客户有时候就会要求按明年4月份的时间点,往前推算20年之内的专利。这样今年有效,明年就到期了的专利就可以不用调查了。
(4)人工筛选・解析
上述讲的各种细节都考虑到了,这个正式的检索式就算做出了,那么需要调查多少件专利也就定了,花的时间和费用也就明确了,这时候一般客户会从调查公司拿到一份计划书。
检索式的制作其实是一个利用数据库来机械筛选的过程,比如检索式检索出来1000件,这1000件无论再怎么对检索式调整里面的分类/关键词/逻辑运算,都不能再缩小了,机械筛选已经到极限了。那么下一步就需要人工来上手了,调查员一件件查看,把不相关的专利去掉,想要的筛选出来。拿着这个机械筛选的清单,按照计划书,开始进行人工筛选。筛选的基准最前面的时候已经定好了,如果中间碰到一些模棱两可的专利引起歧义的话,可能需要再重新确认一下。
判断基准的格式:
- 例:〇需要注意 △参考 ×噪音
根据相关程度,可以把筛选出来的专利分开等级。比如1000件专利,人工筛选后提取出来50件,其中5件专利侵权可能性很高,需要特别注意,标成一个等级。剩下的45件,不侵权,但是技术很类似,可以作为参考归在一类,标成次一个等级。
每件专利选取出来的依据也都可以标一下,比如是在权利要求几、摘要、或者说明书哪个段落记载着什么内容。
- 例:判断依据的内容及记载位置
权利要求1:○○的发明、 由○○、 ○○组成。
摘要: ○○
说明书[0010]: ○○
必要的时候,可以整理成一个判断基准表,这样看起来就更直观了。下图是一个判断基准表的例子,这个调查对象的技术要素很多。每个技术要素的重要度不一样,具备哪几个技术要素可以放到第一级别里,具备哪几个技术要素可以放到第二级别里,这样写出来就比较清楚,不容易搞混。

客户有时会提供一些风险申请人的名字,最开始技术沟通的时候,客户可能会提供一些资料,别的公司的专利申请也好,或者网页的上的宣传资料等等,有时候在调查之前客户心里会事先有个推测,哪个竞争公司出现类似技术的可能性很高。那么,这些申请人在调查的时候就要特别注意。
另外,初步筛选完之后,需不需要进一步对人工筛选出的专利做标签分类、表格/图形化分析、专利地图分析等等,都依据跟客户定好的计划书来做。
(5)精査・报告
人工筛选完之后,就是最后的检查和报告阶段了。
遗漏检查手段有几种:其中一种就是同族专利的互相验证:比如中国专利调查的时候抽取出来了,但是同族美国专利或者日本专利没有抽取出来,这时候就要比对一下,是两个专利的内容确实写的不一样,还是调查员哪里漏看了。
在调查报告里,也可以适当加些调查见解:比如调查过程中发现哪些技术类型的公报多,哪些技术类型的公报没有出现,和预期有哪些一样或不一样的地方? 原先沟通的侵害预防调查观点有几个,但随着调查的进行,发现其中某个观点不具备特征性,筛选出来没有意义,跟客户沟通后调整了基准,最后也可以在报告里说明下。还有调查员在筛选过程中发现的一些直观的见解、或者关于判定基准定义的补充等等,都可以写在报告里。
以上就是日本专利调查的常见流程。

